本記事では、IEA-ETSAPが推進するエネルギーシステムモデリングの標準ツール「VEDA」について、名称の由来から歴史的変遷、VEDA-FE/BEからVEDA 2.0・VEDA Onlineへの世代進化、ライセンス体系、TIMES/GAMSとの関係、Claude Codeを用いた生産性向上方法まで、前提となる必要な全体像を網羅的に解説します。
私は2026年初旬までメルカリのDXチームに所属しAI推進などを担当し、現在はClaude Codeの研修や受託開発を行う株式会社Autoagetの代表をしています。Claude Codeのご相談が増えており、その中で実際に大手のエネルギー関連のコンサルティングを行う企業さまにClaude CodeによるVEDAの生産性向上に携わった経験から、この記事を書いています。
VEDAとは?
VEDAとは、KanORS-EMR が開発したTIMESエネルギーシステムモデルのためのソフトウェアです。
入力(シナリオ設定)を担うFront-End (FE)と、計算結果を多角的に分析・抽出するBack-End (BE)の2つのモジュールで構成されています。
VEDAは1990年代後半からKanORS-EMRにより開発が進められ、2000年以降ETSAPの支援を受けながらTIMES/MARKALコミュニティで利用が拡大しました。
VEDAの起源は1994〜1999年に開発者(KanORS創業者のAmit Kanudia氏)が博士・ポスドク研究の中でMARKALモデル用のデータ移行ツールを作ったことにあります。
2000年にインドに専門チームを設立してVEDAの正式な開発が始まり、米国エネルギー情報局のEIAが運用され、モデルのデータ入力・出力画面として開発されました
つまり、KanORS側が自発的に開発したツールが、ETSAPコミュニティで採用されたという流れです。
VEDAという名称の由来には二つの意味が込められています。
略称としては「VErsatile Data Analyst(多用途データ分析ツール)」を表すと同時に、サンスクリット語で「知識」を意味する言葉でもあります。
開発元のKanORS-EMRがインドに拠点を置くことから、両方の意味を掛けた命名と考えられます。
VEDAを支える3つのコンポーネント
VEDAは単独で動くわけではなく、以下の3つが連携してはじめて機能します。
- VEDA(データ管理UI):Excelベースで入力データを整理・管理する
- TIMES(モデル本体):エネルギーシステムの最適化計算エンジン
- GAMS(数理最適化基盤):線形計画法で実際にソルバー(最適化問題を実際に解くエンジン)を回す
ひとことで言えば、「ある国・地域のエネルギーシステム全体をモデル化して、CO2規制や再エネ目標などの政策制約のもとで、最小コストとなるエネルギーミックスを何十年先まで最適化計算する」ためのツール群です。
VEDAファミリーの構成
VEDAにはいくつかのサブツールがあります。
- VDS(VEDA Data Store):旧VEDA-FE(Front-End)に相当。Excelベースでモデルのインプットデータを管理・編集する
- VDE(VEDA Data Explorer):旧VEDA-BE(Back-End)に相当。TIMESの実行結果を可視化・分析する
- VDT(VEDA Data Template):データ入力のテンプレート構造
- VD(VEDA Database):モデルデータの格納・管理層
旧来はデスクトップ版(VEDA-FE / VEDA-BE)が主流でしたが、現在はWebベースのVEDA Online への移行が進んでいます。
MARKAL / TIMESモデルとは?
MARKALとTIMESはどちらも先述のETSAPが開発したエネルギーシステムの最適化モデルで、TIMESがMARKALの後継です。
MARKAL(MARKet ALlocation)は1970年代後半にIEA-ETSAPで開発されたボトムアップ型のエネルギーシステムモデルです。エネルギーの供給から需要までの技術チェーン全体を線形計画法で最適化し、コスト最小化やCO2排出削減などの条件下で最適なエネルギー技術ミックスを導き出します。
TIMES(The Integrated MARKAL-EFOM System)はMARKALとEFOM(Energy Flow Optimization Model)を統合・発展させた後継モデルで、2000年代から主流になっています。
MARKALでは、年単位の時間スライスが基本で、季節・時間帯別の電力需給変動を十分に表現できませんでした。そのため、季節性の高い太陽光・風力の間欠性を扱うには不十分でした。
また、モデルが大規模化するにつれ、入力データの管理・整合性確保が大変になりました。
そこで、再エネの変動性への対応を含め、MARKALよりより柔軟な時間表現・多地域表現・技術表現を可能にするためTIMES モデルが開発されました。
VEDAにはどのような種類がある?
VEDAの種類は大きく「世代」と「ライセンスティア」の2軸で整理されます。
世代については、歴史的変遷として下記の3つのバージョンが存在します。
VEDA-FE / VEDA-BE(旧世代)
VB6/MS Accessベースで、20年以上かけて機能が追加されました。VEDA-FE(Front End)がデータ入力・モデル構築、VEDA-BE(Back End)が結果分析と、2つの別アプリケーションに分かれていました。現在は開発終了しています。
VEDA 2.0(現行・ローカル版)
C#.NETでUIを構築し、PostgreSQLをバックエンドに使用。VEDA-FE + VEDA-BEを1つのアプリケーションに統合しています。Windowsで動作し、Macでは動作できません。
VEDA Online(VO)
ブラウザ経由でVEDA-TIMESのコア機能を提供するクラウド版で、モデルフォルダをGitHubに置いて利用する形式。同期、ブラウズ、実行管理、結果分析、レポートに対応しています。

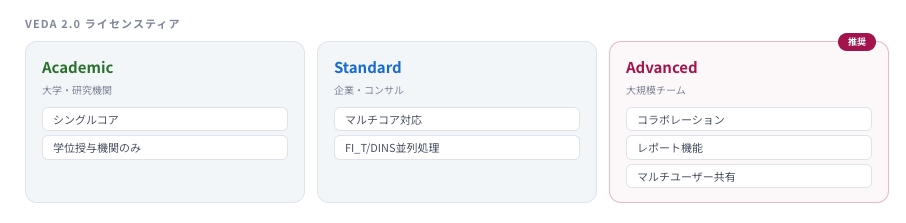
VEDA 2.0には3つのライセンスティアがあります。Academic版は学位授与機関のみが利用可能で、シングルコアでの動作となります。
Standard版は企業やコンサルティングファーム向けで、マルチコアに対応しFI_TやDINSタグの並列処理が可能なため、大規模モデルの処理速度が向上します。
Advanced版はStandard版の機能に加え、コラボレーション機能・レポート機能・マルチユーザー共有を備えており、複数のモデラーが同一サーバー上で同じモデルを扱うチーム運用に適しています。
VEDAはどうすれば利用できる?
日本はETSAP加盟国であるため、2つ入手のルートがあります。
① VEDA Online(クラウド版)
こちらのURL からアカウント登録できます 。学生向けには無料版が提供されていて、承認された教育機関のメールアドレスで登録すれば無料プラットフォームにアクセスできます。ただしローカルでのモデル実行やローカルからの結果アップロードなど一部機能は制限されます
② VEDA 2.0(ローカルインストール版)
VEDA 2.0を登録すると、ETSAP Liaison Officerにリクエストが送られ、評価用のGAMSライセンスファイルが発行されます
ダウンロードはGitHubから行うことができます。 https://github.com/kanors-emr/Veda2.0-Installation
GAMSも必要
TIMESはGAMS(General Algebraic Modeling System)で書かれているため、VEDAの利用にはGAMSも必要です。 詳細は後述します。
トレーニング
ETSAPは年2回のトレーニングコースを提供しており、基礎コース(3日間)ではETSAP加盟国は無料、企業は€1,200(約221,700円)、大学は€750 (約 138,600円)です。教育機関向けにはVEDA Onlineの無料アクセスも提供されています。
動作環境
Windows 8 / Windows Server 2012以上が必要で、VEDA 2.0の最新版ではMicrosoft Excelが不要になっています。バックエンドはPostgreSQLで、C#.NETアプリケーションです。
GAMSとは?
GAMS(General Algebraic Modeling System)は、数理最適化問題を記述・実行するための汎用モデリング言語です。
TIMESモデルのソースコードはすべてGAMSで書かれており、VEDAから投入されたデータをもとに線形計画問題を組み立て、ソルバーを呼び出して最適解を求めます。
GAMS自体は商用ソフトウェアで、VEDA・TIMESとは別にライセンスが必要ですが、VEDA登録時にETSAPリエゾンオフィサーを通じて同様に評価版ライセンスを取得できます。
例えば、 GAMS公式チュートリアル にある「輸送問題」のコードを簡略化すると、以下のようになります。
この例は「2つの工場から3つの市場へ、輸送コストを最小化しながら商品を出荷する」という最適化問題です。
GAMSでは、集合(Set)・パラメータ(Parameter)・変数(Variable)・制約式(Equation)を数学の記法に近い形で記述し、最後の Solve 文でソルバーに投げて最適解を求めます。TIMESではこの仕組みを使って、エネルギー技術・燃料・需要の組み合わせをはるかに大規模に定義し、数十年先までの最適なエネルギーシステム構成を算出しています。
Set i '工場' / Seattle, San-Diego /
j '市場' / New-York, Chicago, Topeka /;
Parameter a(i) '工場の供給量'
/ Seattle 350, San-Diego 600 /;
Parameter b(j) '市場の需要量'
/ New-York 325, Chicago 300, Topeka 275 /;
Variable x(i,j) '出荷量'
z '総輸送コスト';
Equation cost '目的関数'
supply(i) '供給制約'
demand(j) '需要制約';
cost.. z =e= sum((i,j), c(i,j)*x(i,j));
supply(i).. sum(j, x(i,j)) =l= a(i);
demand(j).. sum(i, x(i,j)) =g= b(j);
Model transport /all/;
Solve transport using LP minimizing z;実際のシミュレーションフロー
実際の分析は、モデル設計 → データ入力 → 実行 → 結果確認 → シナリオ比較 → レポート化 の流れで進めていきます。
VEDA + TIMESのシミュレーションフローを解説します。
全体の流れ
データ準備 → モデル構築 → GAMS変換 → ソルバー実行 → 結果分析
この一連のパイプラインが1回のシミュレーションサイクルです。
ここでエラーがあるとモデルが走らないため、デバッグに時間がかかる部分です。
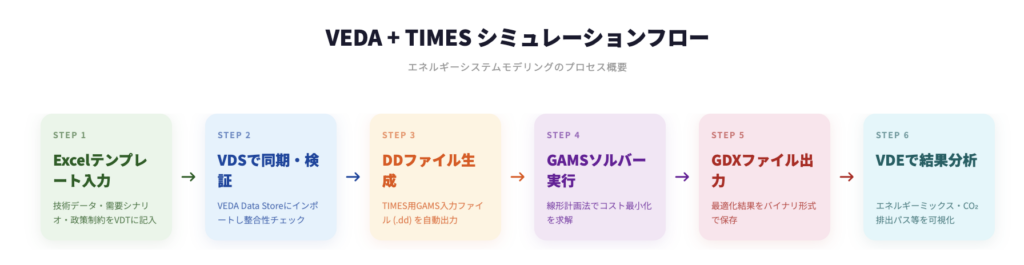
Step 1:Excelテンプレート入力
VDTと呼ばれるExcelテンプレートに、シミュレーションの前提条件を記入します。具体的には、技術データ(各技術の効率・コスト・寿命など)、需要シナリオ(将来のエネルギー需要予測)、政策制約(CO2排出上限や再エネ導入目標)などです。
テンプレートはSysSettings、BaseTrans、SubRES、Trade、Demandsなど複数のExcelファイルで構成されます。
Step 2:VDSで同期・検証
入力したExcelデータをVDS上で「Synchronize(同期)」します。データが内部データベースに取り込まれ、整合性チェックが走ります。技術間のエネルギー財の入出力整合、時間スライスの定義、パラメータの単位整合などが検証されます。
ここでエラーがあるとモデルが走らないため、デバッグに最も時間がかかるポイントです。
Step 3:DDファイル生成
VDSが内部データを DDファイル(.dd) に変換します。DDファイルはTIMESモデルのGAMS入力ファイルで、SET定義やPARAMETER定義がテキスト形式で書かれています。モデルの規模によっては数十〜数百のDDファイルが生成されます。
Step 4:GAMSソルバー実行
GAMSランタイムが、TIMESモデルを線形計画問題(LP)または混合整数計画(MIP)として解きます。目的関数はシステム全体のトータルコスト最小化(割引後)で、需要充足・排出上限・技術制約・資源上限などが制約条件です。
ソルバーにはCPLEXやGUROBIなどが使われ、計算時間はモデル規模により数分〜数時間かかります。
Step 5:GDXファイル出力
最適化の結果は GDXファイル(GAMS Data Exchange) というバイナリ形式で保存されます。GDXにはセット定義、パラメータ、最適化結果の変数(設備容量、エネルギーフローなど)、方程式の双対値(限界コスト)が格納されます。
Step 6:VDEで結果分析
GDXファイルをVDEに読み込んで、結果を可視化・分析します。エネルギーミックスの推移、技術別投資額、CO2排出パス、限界削減コスト(シャドウプライス)などをグラフや表で確認できます。
結果を見て「再エネコストを変えたら?」「原子力を制約したら?」などパラメータを変更し、Step 1に戻ります。政策提言には通常、10〜数十のシナリオ比較が必要です。
自動化のボトルネック
- Step 1のExcelデータ投入… 手作業が多く、ヒューマンエラーの温床
- Step 2-3の同期・変換… VDSのGUI操作が必須で、自動化しにくい
- Step 5の結果抽出・レポート… GDXからの定型的なグラフ・表の生成
- Step 6のシナリオ管理… パラメータ組み合わせの管理と一括実行
AI活用で効率化できるポイント
VEDA/TIMESのワークフローには、AI自動化と相性の良いポイントがいくつかあります。
すでにClaude Codeと、メルカリなどのエンタープライズIT業界で実践されている業務自動化のプラクティスを組み合わせて活用することで、大幅に工数を減らせるポイントが出始めています。
- Excelテンプレートの作成・メンテナンス:膨大なExcelワークブックの整合性チェックや自動生成
- リサーチの情報収集:政府系のサイトから関連情報を毎日自動で収集
- シナリオ設計:政策制約の組み合わせパターンを自然言語から自動生成
- 結果の解釈・レポーティング:GDXファイルからの定型グラフ・表の生成、最適化結果の要約・比較分析
- エラー検出・デバッグ:モデルが解けない時(infeasible)の原因特定をAI支援
- データ収集・前処理:各国のエネルギーバランスデータの取り込み自動化
特にStep 1のデータ投入とStep 6の結果抽出・レポート作成は手作業が多く、ヒューマンエラーの温床になりやすい工程です。Claude Codeなどのコーディングエージェントと組み合わせることで、これらのプロセスを大幅に効率化できる可能性があります。
まとめ
VEDAは、エネルギーシステムの将来像をシミュレーションするための標準的なプラットフォームです。Excel入力 → VDS同期 → DDファイル生成 → GAMSソルバー実行 → GDX結果出力 → VDE分析という6ステップのサイクルを回しながら、最適なエネルギーミックスを探索します。
脱炭素社会に向けたエネルギー政策の議論が加速するなか、VEDA/TIMESを使ったモデリングの重要性は今後さらに高まっていくでしょう。同時に、手作業が多い既存のワークフローにAI自動化を組み合わせることで、分析の質とスピードを両立させることが求められています。
株式会社Autoagentでは、VEDA/TIMESワークフローのAI自動化支援を行っています。Claude Codeなどの生成AI ツールを用いたエネルギーモデリング業務の効率化にご関心のある企業さまは、お気軽にお問い合わせください。